
NL2SQL 是一个偏工业化的问题,SQL语句要是没有办法满足高准确率的话很难落地。目前也有很多解决方案去做这个事情,这里参考一些资料设计了一个通用的NL2SQL框架。
架构
定义梳理:
| 符号 | 定义 |
|---|---|
| q | 问题 |
| rewrited q | 经过问句改写之后的问题 |
| e(q) | embedding of q |
| s | sql query |
| D | database schema 信息,表格定义 |
| Q | 三元组$(q_i, s_i, D_i)$ |
| $Q_{up}$ | 大于阈值的的Q的集合 |
| $Q_{down}$ | 小于阈值的的Q的集合 |
| $P$ | 预生成SQL模型 |
| CR_p(q) | code representation prompt |
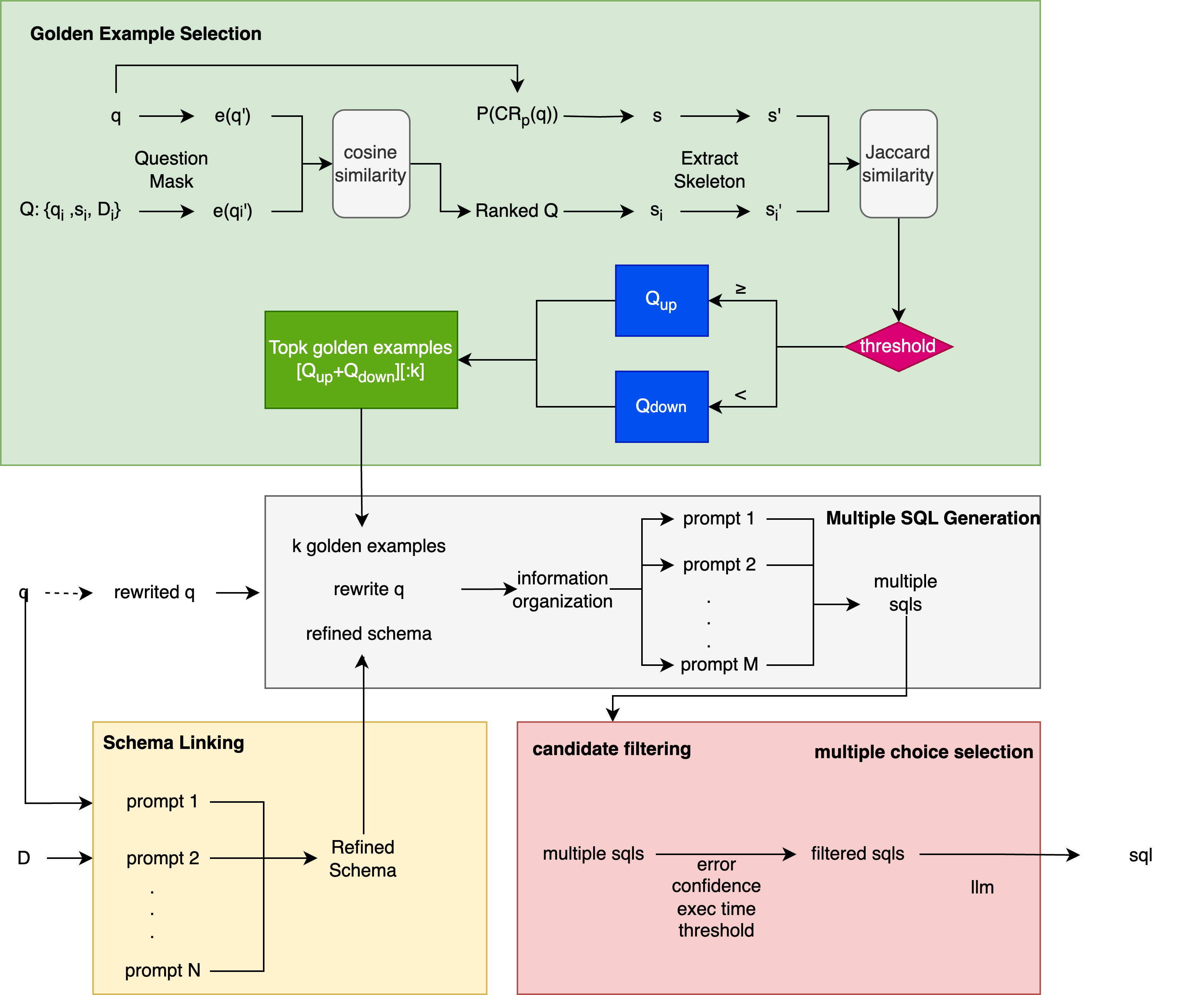
如上图,整体架构分为上下两部分,上部部分负责在库中选择golden examples,下半部分负责 schema linking, 数据表和表头的选择,并将上班部分选中的golden examples进行组合(information organzation)为不同的prompts,通过调高温度系数同时生成多条SQL结果。然后进行 candidate filtering 过滤策略看 filtering strategy, 最后将过滤之后的 filtered sqls 给大模型来做一个multiple choice selection,选择出最优的SQL。
原理
Golden Example Selection
在大模型生成中,fewshot是一个很重要的手段,而传入的examples和问题的相关程度以及生成的SQL的skeleton很大程度上影响了最后的结果生成。基于此,先对问题进行了cosine similarity的计算,对Q进行排序;然后基于SQL的Skeleton来计算Jaccard Similarity来进行划分$Q_{up}$和$Q_{down}$, 选出最后的k个examples作为fewshot的例子。
Query Rewrite
问句改写常常被认为是一个可以省略的步骤,如果问题无关上下问的话,可以尽可能保留查询问句的原貌,因为改写可能会对句子中的某些 column name 进行错改,导致SQL结果错误。
Schema Linking
对于数据库资料的选择也很重要,这里对于表的选择可以通过对表进行表头的全匹配来进行规则筛选,也可以通过对大模型来进行筛选,一般根据业务特性来选择。
如果表名确定之后,表头的选择实际上并不会对结果造成特别大的影响,当然也可以通过选择表格的方式进行筛选,可以减少后面的误差。
Information Organization
在选择Golden Examples之后,需要对Golden Examples进行information organization,即将Golden Examples进行组合,生成不同的prompts。
组合的策略包括:
- SQL Only
- Question + SQL
- Question + SQL + Table Scehma
Candidate Filtering
当生成N条SQL时,就需要对这些SQL语句进行过滤。
- 筛除所有执行错误的SQL。
- 将所有的SQL按照执行结果进行分组,然后计算置信度。 相同结果的SQL语句的个数 / 所有的SQL语句;
- 保留每组中执行速度最快的SQL语句。
- 过滤置信度小于threshold的sQL语句。
Multiple Choice Selection
将Candidate Filtering中过滤之后的SQL语句进行多选,选择出最优的SQL。
总结
NL2SQL可以考虑用更加运营化的思路去进行设计,比如说对于某一个业务的表格的选择,可以考虑用业务规则来筛选,而不是用大模型来筛选。Golden Examples的选择可以通过人工增加那些badcases来兜底。
资料参考
博客
NL2SQL基础系列(1):业界顶尖排行榜、权威测评数据集及LLM大模型(Spider vs BIRD)全面对比优劣分析[Text2SQL、Text2DSL]
Text-to-SQL小白入门(12)Awesome-Text2SQL开源项目star破1000_text2sql有哪些开源项目-CSDN博客
论文
MAC-SQL
MAC-SQL: A Multi-Agent Collaborative Framework for Text-to-SQL
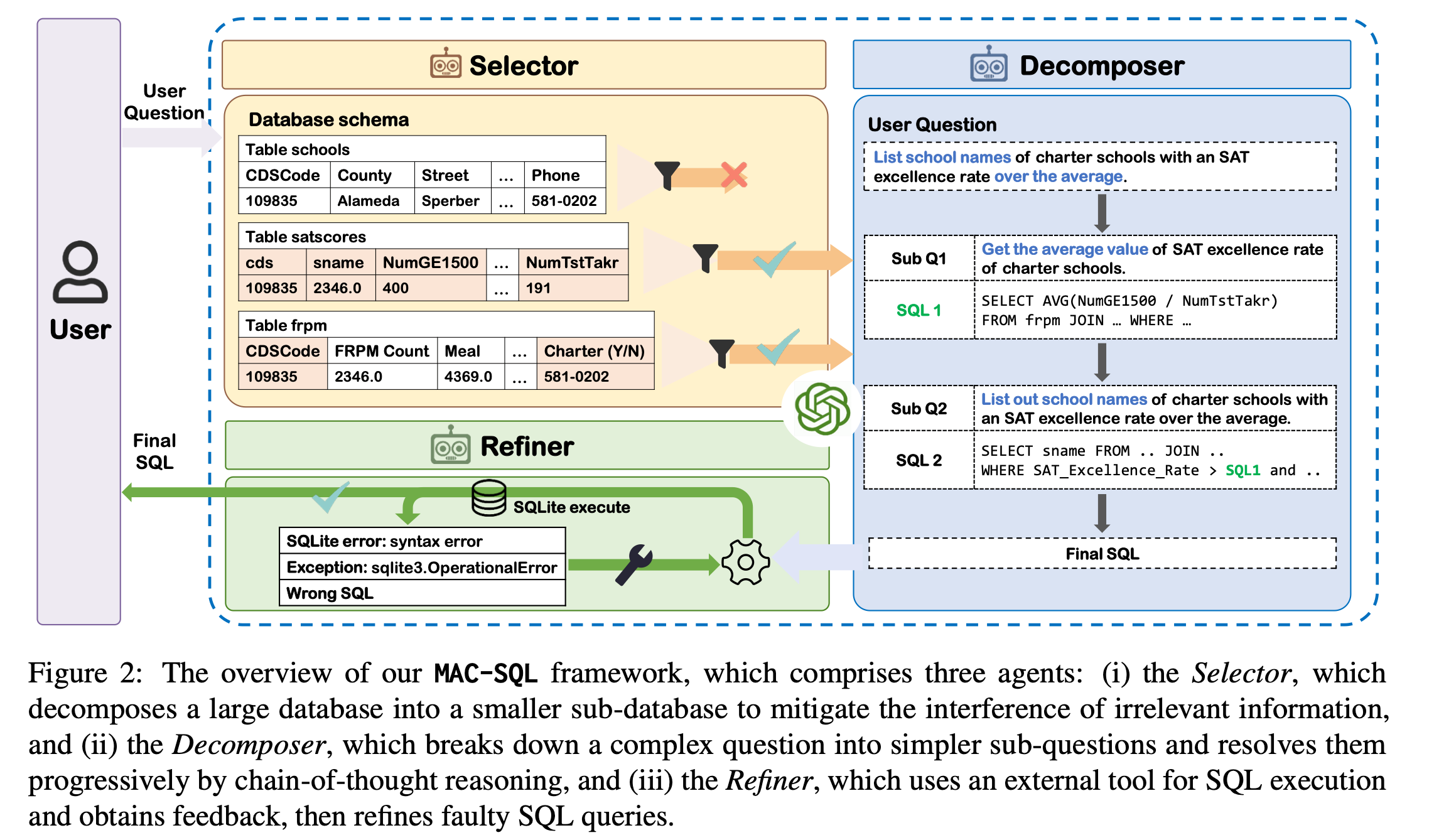 多阶段使用大模型去做text2sql,Selector来选择database schema,Decomposer来进行Question的拆分和生成,Refiner对SQL进行校验并重生成。
多阶段使用大模型去做text2sql,Selector来选择database schema,Decomposer来进行Question的拆分和生成,Refiner对SQL进行校验并重生成。
MCS-SQL
MCS-SQL: Leveraging Multiple Prompts and Multiple-Choice Selection For Text-to-SQL Generation
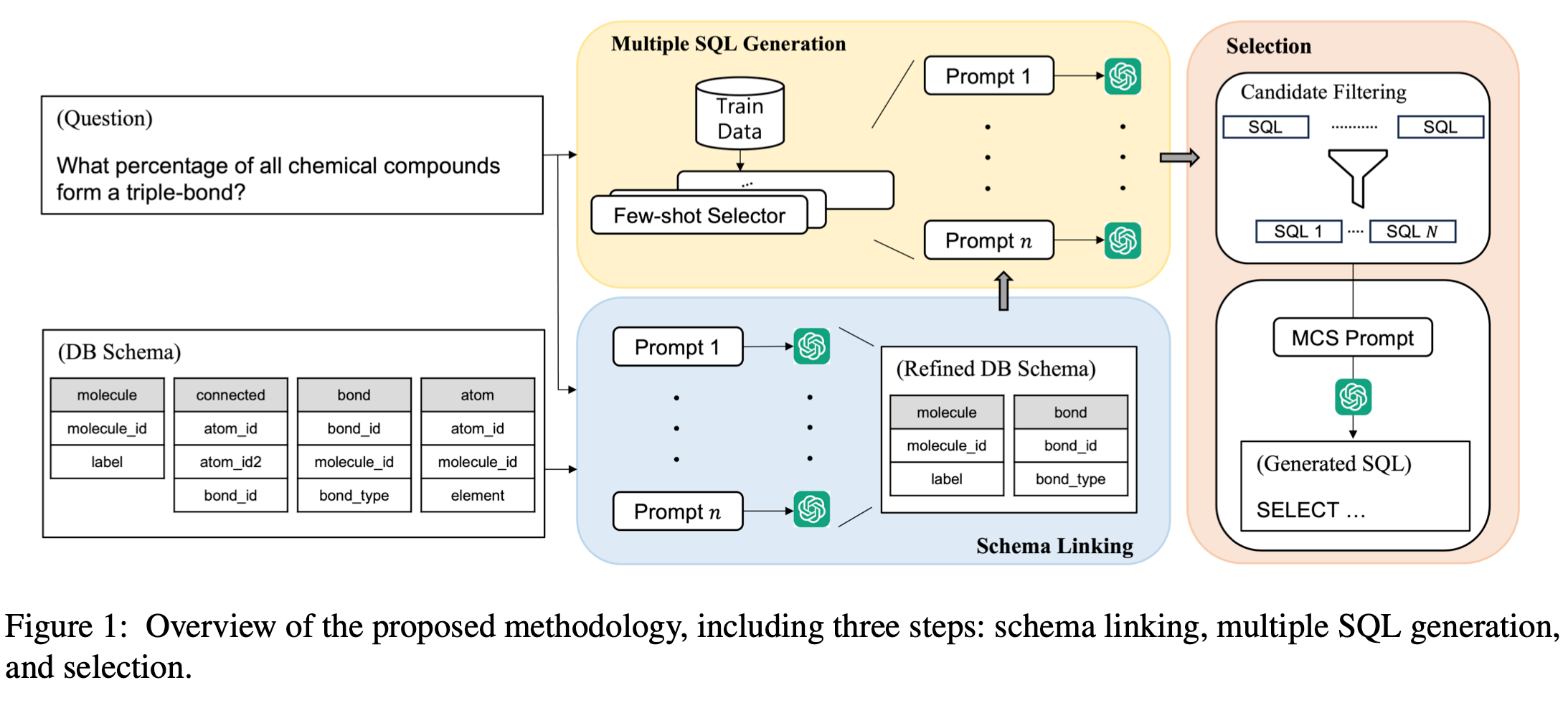 特点是采用并行生成多条结果的方式,本质上还是Schema Linking来选择Tables和columns,通过embedding的方式来选择Golden Examples作为之后SQL生成的ICL(in-context learning)。生成N条SQL之后,通过一种过滤方式(分组+置信度+效率排序)选出M条SQL,最后让大模型去哪条是正确的SQL。
特点是采用并行生成多条结果的方式,本质上还是Schema Linking来选择Tables和columns,通过embedding的方式来选择Golden Examples作为之后SQL生成的ICL(in-context learning)。生成N条SQL之后,通过一种过滤方式(分组+置信度+效率排序)选出M条SQL,最后让大模型去哪条是正确的SQL。
DAIL
Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation
 DAIL这篇论文的特点在于设计了一种另类的embedding,对question进行masked(question中出现的表名用【mask】表示)之后再去挑选Golden examples,然后再通过Jaccord Similarity来进行重排,下面这个是伪代码,具体细节可以看论文。
DAIL这篇论文的特点在于设计了一种另类的embedding,对question进行masked(question中出现的表名用【mask】表示)之后再去挑选Golden examples,然后再通过Jaccord Similarity来进行重排,下面这个是伪代码,具体细节可以看论文。
文档信息
- 本文作者:pnightowl
- 本文链接:https://pnightowlzy.github.io/2024/05/01/nl2sql/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)