
Material
- Course: https://www.deeplearning.ai/short-courses/finetuning-large-language-models/
Why finetuning
什么是微调? 微调是将让模型具备特定回复风格和领域能力,例如chatgpt的问答回复,github copilot的代码能力等。 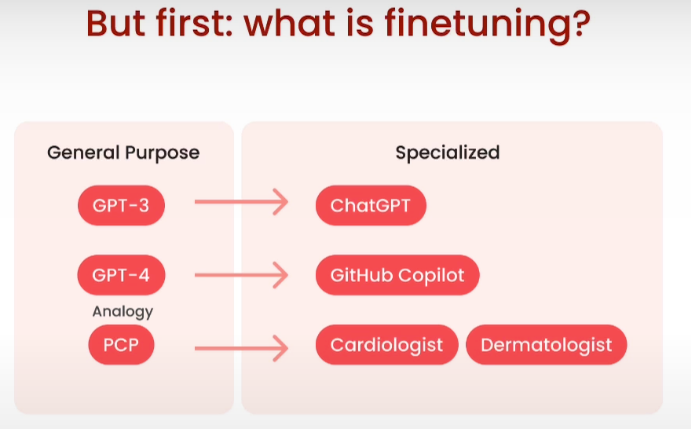
Prompt Engineering vs. Finetuning
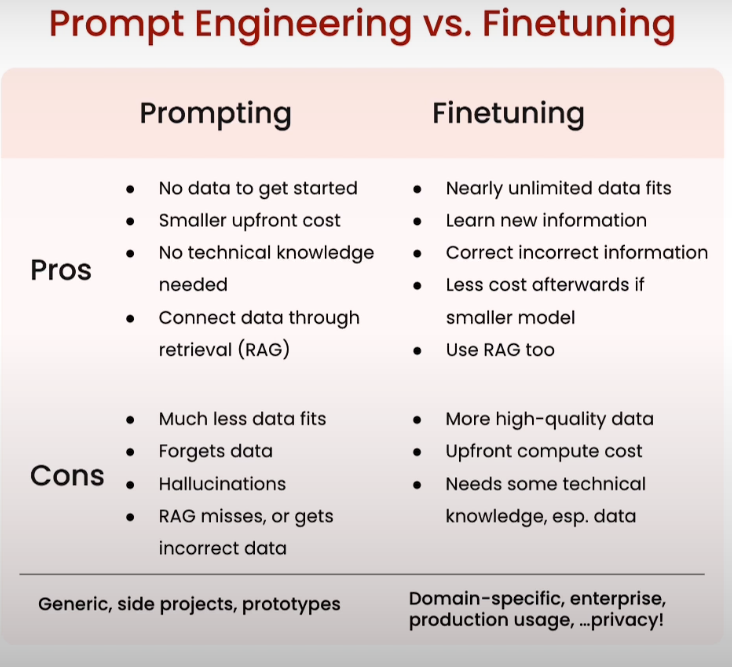
Prompt Engineering
Pros
- 不需要训练数据
- 更少的预付成本
- 不需要掌握底层原理
- 可以使用RAG技术获得额外的数据 Cons
- 不能适配更多的数据
- 数据遗忘
- 幻觉
- RAG召回的质量影响效果
Finetuning
Pros
- 需要尽可能多的数据
- 可以掌握最新产生的信息(新闻、前沿知识等)
- 调整之前测试出现的错误信息
- 如果能训练出小的模型最终的成本降低
- 同样能够使用RAG Cons
- 需要更高质量的数据
- 计算成本高
- 需要知道的底层逻辑很多,微调技术,数据处理等。
Benefits of finetuning your own LLM
Performance
- 降低幻觉
- 增强一致性(公司价值观,产品策略等)
- 减少不想要模型输出的信息 Privacy
- 作为预制软件,私有化
- 防止数据泄漏
- 不会侵权 Cost
- 降低每次的请求
- 增加透明性
- 更好的控制 Reliability
- 实时控制
- 更低的时延
- 节制(话题相关)
Examples
baseModel和chatModel(finetuned) 的区别,没有finetune前的模型回答的效果会比较奇怪,容易出现重复的话,而且对话的风格也不像人人对话一般。
Where finetuning fits in
Pretraining
- Model at start
- zero knowledge about the world
- can not form English words
- Next token prediction
- Giant corpus of text data
- Oftern scraped from the internet: “unlabeled”
- Self-supervised learning
- After Training
- learns language
- learns knowledge
What is “data scraped from the internet”
- Often not publicized how to pretrain
- Open-source pretraining data: “The Pile”
- Expensive & time-consuming to train
Limitations of pretrained base models
base 模型的训练数据:
Geography Homework Name: Q: What's the capital of India? Q: What's the capital of Kenya? Q: What's the capital of France?输入:What is the capital of Mexico? 输出:What is the capital of Hungary?
base模型在没有进行数据微调的情况下,回答效果和预训练数据的质量和特征有很大关系。
Finetuning after pretraining
Corpus Texts –> Pretraining –> Base Model Corpus Texts –> Pretraining –> Base Model –> High quality data –> Finetuning –> Finetuned Model Finetuning 通常需要:
- 自监督的无标注数据
- 标注数据
- 不需要预训练时那么多数据
- 可以作为后续被使用(翻译,chatbots,codepilot等) Finetuning for generative tasks is not well-defined:
- 更新整个模型
- 训练目标:next token prediction
What is finetuning doing for you?
这里的base model,相当于一个具有很多知识的大脑,但是他并不知道该怎么输出这些信息,所以微调这个过程就是要让模型知道什么时候应该输出什么样的知识,这是一个Gain Knowledge通过Behavior Change让模型能够真正的被使用。
First time finetuning
- Identify task(s) by prompt-engineering a large LLM
- Fine tasks that you see an LLM doing ~ok at
- Pick one tsk
- Get ~1000 inputs and outputs for the task
- Better that the ~OK from the LLM
- Finetune a small LLM on this data
Examples
这里的例子主要是构造训练数据,需要通过构造特定的输入,让模型能够学会我们想要的回答的格式。
- Finetune a small LLM on this data
Instruction finetuning
Instruction finetuning(reasoning, routing, copilot, caht, agents) is part of finetuning. data: FAQs, Customer support service, etc.
Training Process
Data Prep -> Training -> Evaluation -> Data Prep …
Examples
比较了base model和finetuning model的实际效果。
Data preparation
Garbage In -> Garbage out
Steps
- Collect instruction-response pairs
- Concatenate pairs
- Tokenize: Pad, Truncate
- Split into train/test
Example
整个流程跟训练其他的模型并没有什么很大区别。
Evaluation and iteration
Human Evaluation Test Suites Elo Rankings
LLM Benchmarks: Suite of Evaluation Methods
Common LLM benchmarks
- ARC is a set of grade-school questions
- HellaSwag is a test of common sense
- MMLU is a multitask metric covering elementary math, US history, computer science, law and more
- TruthfulQA measures a model’s prepensity to reproduce falsehoods commonly found online.
Consideration
Pratical approach to finetuning
- Figure out your task
- Collect data related to the task’s inputs/outputs
- Generate data if you don’t have enough data
- Finetune a small model(e.g. 400M-1B)
- Vary the amount of data you give the model
- Evaluate your LLM to know what’s going well vs. not
- Collect more data to improve
- Increase task complexity
- Increase model size for
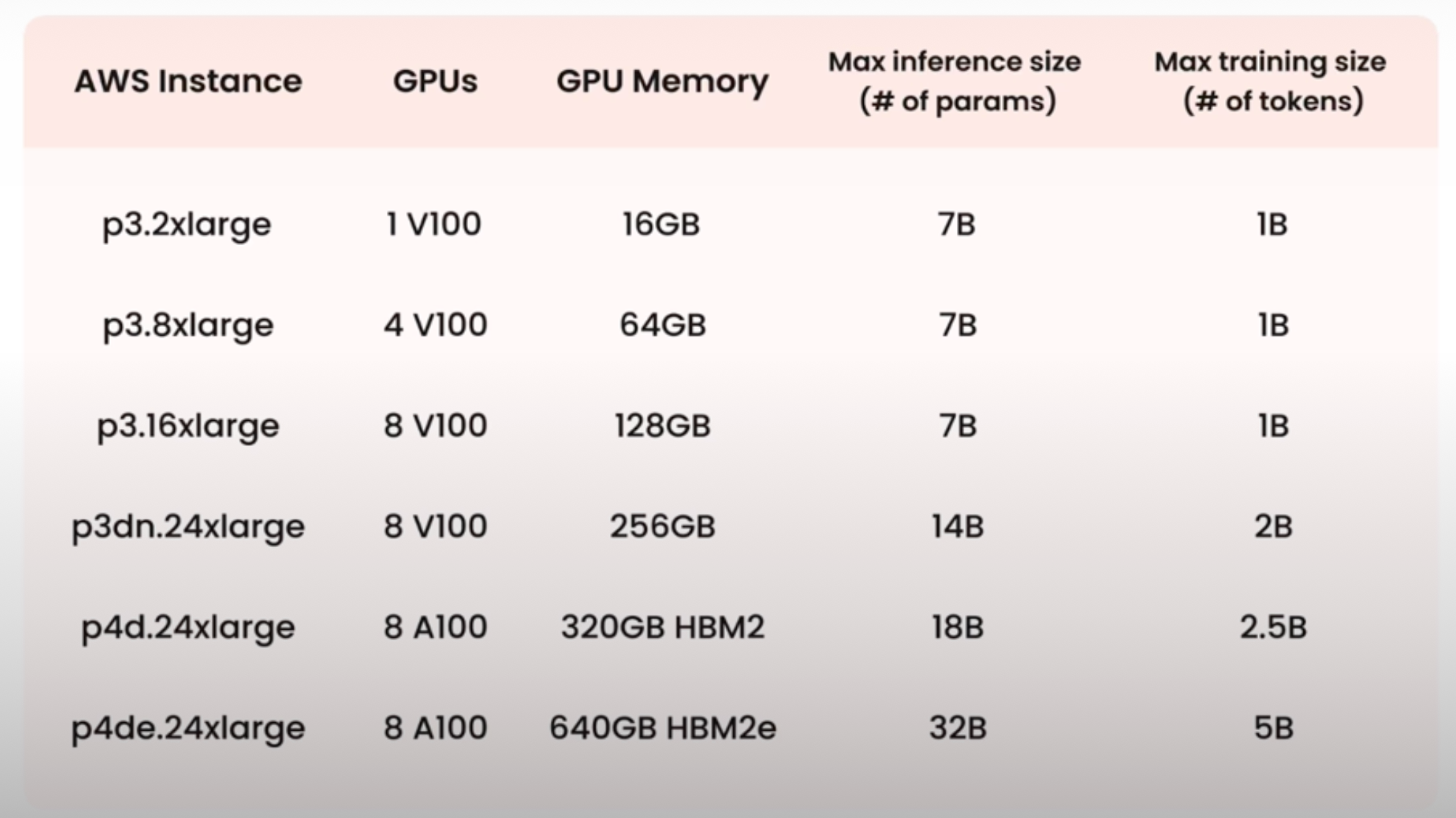
Model size x Compute
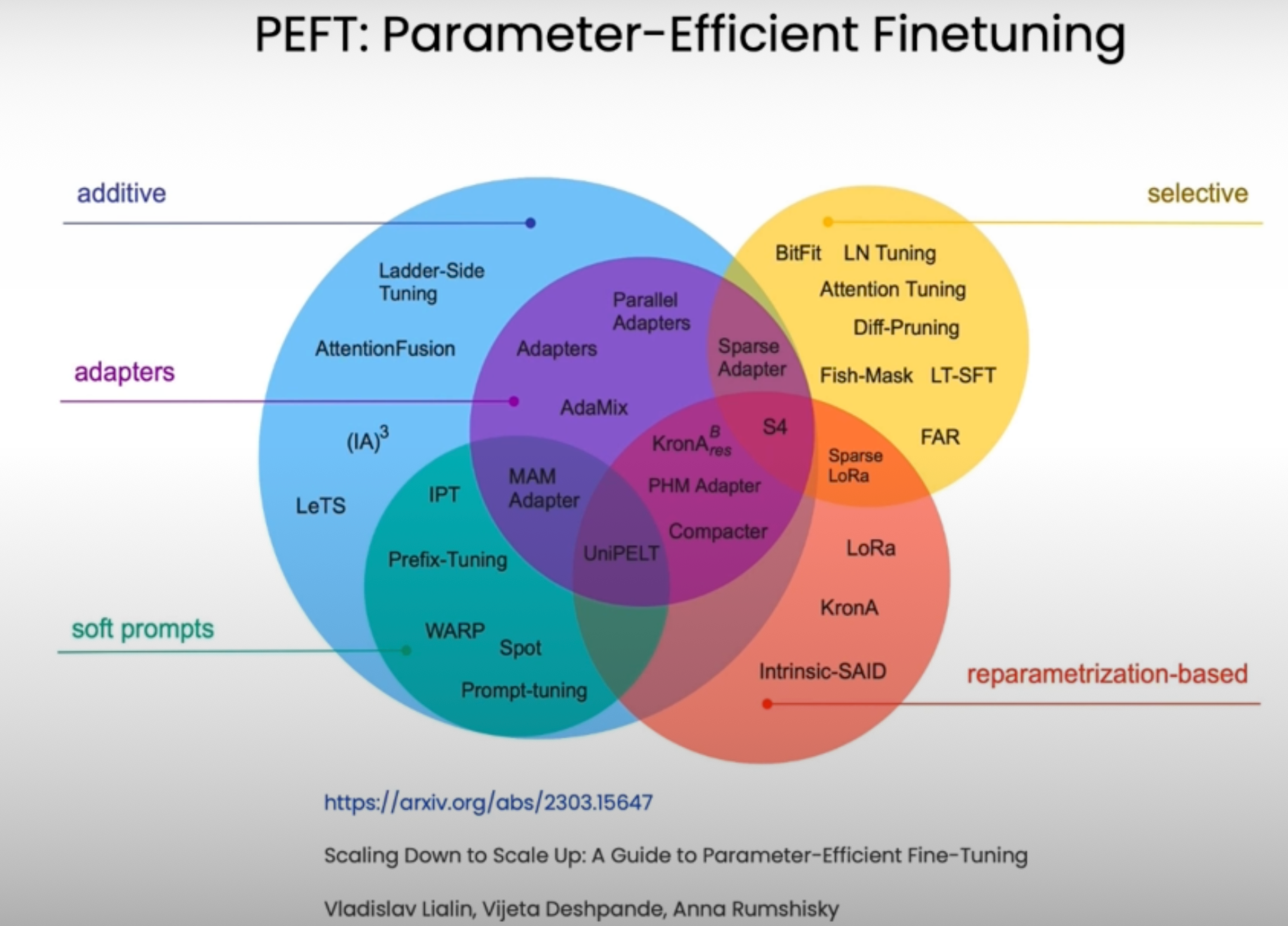
Parameters Efficient finetuning
Practice
跑通训练脚本:https://learn.deeplearning.ai/courses/finetuning-large-language-models/lesson/6/training-process
文档信息
- 本文作者:pnightowl
- 本文链接:https://pnightowlzy.github.io/2024/07/12/llm-finetuning/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)